Some of the most powerful (and interesting) features of working with R on corpus analysis involve exploring technical features of texts. In this script, I use a some well-known R packages for text analysis like tidyr and tidytext, combined with ggplot2, which I used in the previous post, to analyze and visualize textual data.
This comnbination allows us to do things like find word frequences in particular subsets of the corpus. In this case, I’ve selected for Rudyard Kipling and charted the 10 words he uses most frequently in the corpus:
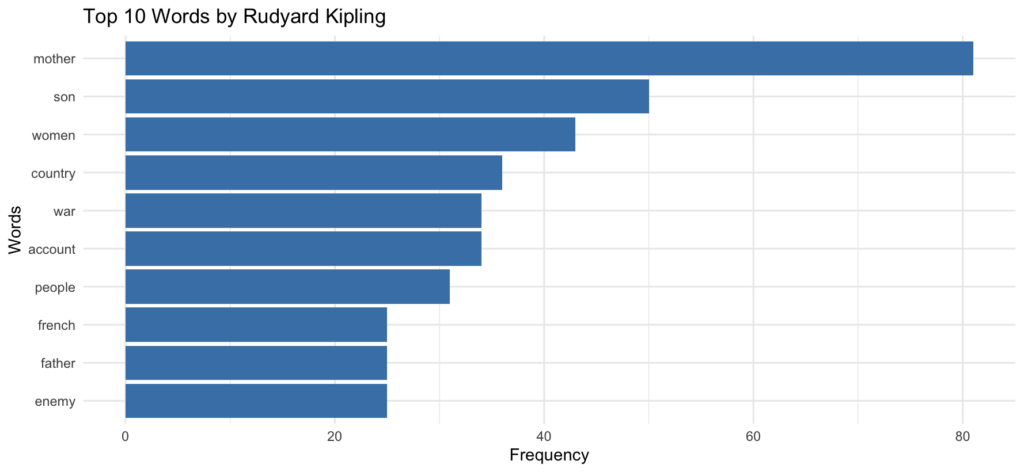
To accomplish this, I filtered for texts by Kipling, unnested the tokens, generated a word count, and plotted the words in a bar graph. Here’s the code:
# Filter for a specific author in the corpus and tokenize text into words. Here
# I've used Kipling
word_freq <- empire_texts %>%
filter(author == "Kipling, Rudyard") %>%
unnest_tokens(word, text) %>%
# Remove stop words and non-alphabetic characters
anti_join(stop_words, by = "word") %>%
filter(str_detect(word, "^[a-z]+$")) %>%
# Count word frequencies
count(word, sort = TRUE) %>%
top_n(10, n)
# Create bar graph
ggplot(word_freq, aes(x = reorder(word, n), y = n)) +
geom_bar(stat = "identity", fill = "steelblue") +
coord_flip() +
labs(title = "Top 10 Words by Rudyard Kipling",
x = "Words", y = "Frequency") +
theme_minimal()I also selected the top 10 bigrams and filtered for author, in this case H. Rider Haggard:
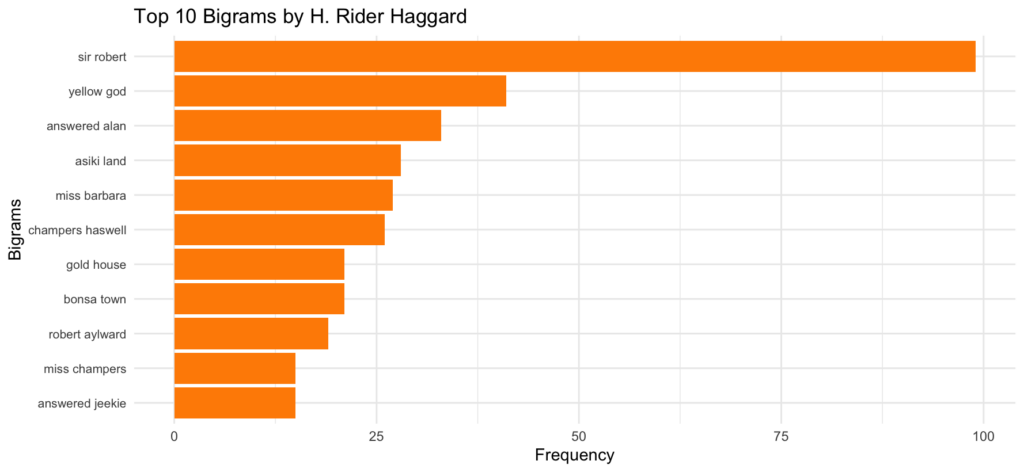
In this case, I was just interested in seeing any bigrams, but depending on your analysis, you might want to see, for example, what the first word in a bigram is if the second word is always “land.” You could do that by slightly modifying the script and including a line to filter word2 as land. For example:
bigram_freq <- empire_texts %>%
filter(author == "Haggard, H. Rider (Henry Rider)") %>%
unnest_tokens(bigram, text, token = "ngrams", n = 2) %>%
filter(!is.na(bigram)) %>%
separate(bigram, into = c("word1", "word2"), sep = " ") %>%
# Filter for bigrams where word2 is "land"
filter(word2 == "land") %>%
filter(!word1 %in% stop_words$word) %>%
unite(bigram, word1, word2, sep = " ") %>%
count(bigram, sort = TRUE) %>%
top_n(10, n)Finally, I’ve used TF-IDF (Term Frequency-Inverse Document Frequency) to chart the top 5 most distinctive words by title. The titles are randomly generated from the corpus with set seed (which I’ve set to 279 in my script), but you could regenerate with random titles by changing the set seed number.
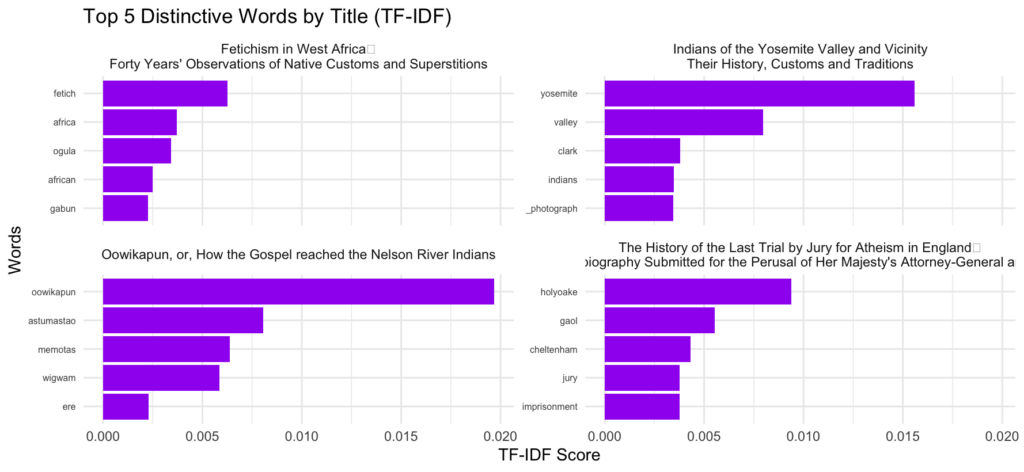
Here’s the script for that:
# Filter, tokenize, and calculate TF-IDF
tfidf_data <- empire_texts %>%
filter(title %in% sample_titles) %>%
unnest_tokens(word, text) %>%
anti_join(stop_words, by = "word") %>%
count(title, word, name = "n") %>%
bind_tf_idf(word, title, n) %>%
# Get top 5 words per title by TF-IDF
group_by(title) %>%
slice_max(order_by = tf_idf, n = 5, with_ties = FALSE) %>%
ungroup()
# Create faceted bar plot
ggplot(tfidf_data, aes(x = reorder_within(word, tf_idf, title), y = tf_idf)) +
geom_bar(stat = "identity", fill = "purple") +
facet_wrap(~title, scales = "free_y") +
coord_flip() +
scale_x_reordered() +
labs(title = "Top 5 Distinctive Words by Title (TF-IDF)",
x = "Words", y = "TF-IDF Score") +
theme_minimal() +
theme(axis.text.y = element_text(size = 6))Needless to say, you could run this with as many titles as you chose, though the graph gets a little wonky if you run too many–and the process can slow down considerably depending on the size of the corpus.
It’s worth noting that these plots can be written to an R document called Quarto and published on the web (with a free account) via RPubs. This can help if want to use charts for a presentation, or even if you just want the chart to display online in a more versatile environment. Maybe I’ll write a series on creating presentations in RStudio at some point.
Here’s the third and final script for our British Empire sentiment analysis.
Stay tuned for the next project.